Little talks on: Mongoose with Pagination and Aggregation Pipelines.
This article is about my new app Youtube-Twitter
Tokens-
Lets talk about tokenization-
Why its important? and What is a Token?
Tokens are pieces of data that carry just enough information to facilitate the process of determining a user's identity or authorizing a user to perform an action. All in all, tokens are artifacts that allow application systems to perform the authorization and authentication process.
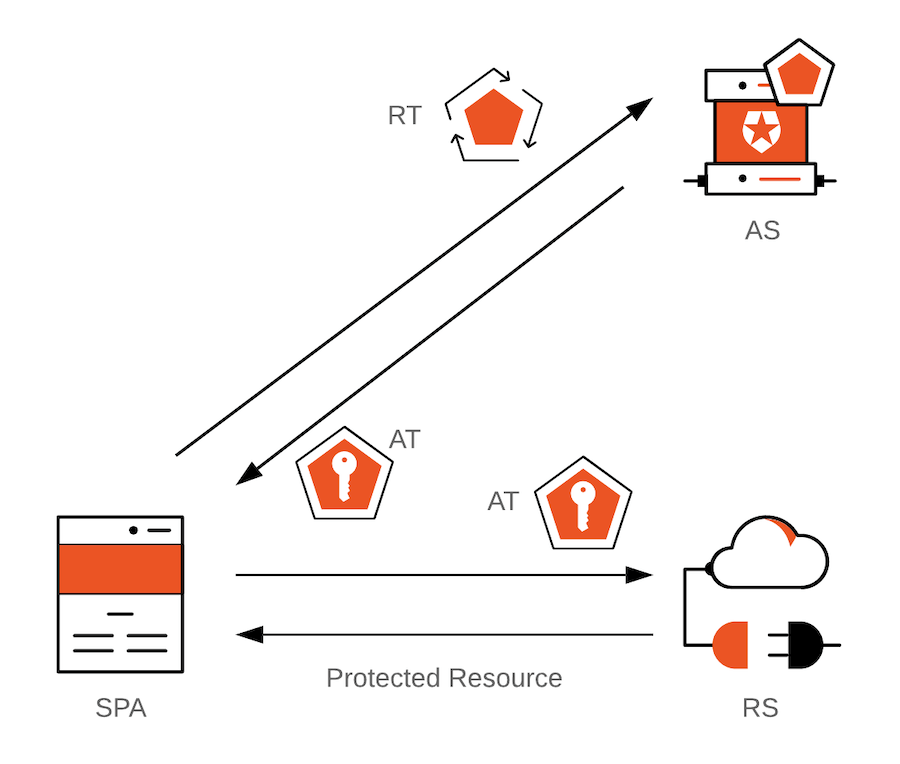
Access Token: When a user logins in, the authorization server issues an access token, which is an artifact that client applications can use to make secure calls to an API server. When a client application needs to access protected resources on a server on behalf of a user, the access token lets the client signal to the server that it has received authorization by the user to perform certain tasks or access certain resources.It's important to highlight that the access token is a bearer token. Those who hold the token can use it. The access token then acts as a credential artifact to access protected resources rather than an identification artifact. Malicious users could theoretically compromise a system and steal access tokens, which in turn they could use to access protected resources by presenting those tokens directly to the server. As such, it's critical to have security strategies that minimize the risk of compromising access tokens. One mitigation method is to create access tokens that have a short lifespan: they are only valid for a short time defined in terms of hours or days. There are different ways that a client application can get a new access token for a user. For example, once an access token expires, the client application could prompt the user to log in again to get a new access token. Alternatively, the authorization server could issue a refresh token to the client application that lets it replace an expired access token with a new one.
Refresh Token: As mentioned, for security purposes, access tokens may be valid for a short amount of time. Once they expire, client applications can use a refresh token to "refresh" the access token. That is, a refresh token is a credential artifact that lets a client application get new access tokens without having to ask the user to log in again.
Parsing & Hashing
Parsing is the process of breaking down data into smaller, more manageable components. It can be used to analyze and interpret the syntax of a program, text, or data structure.
Cookies Parser (NPM Package): Cookie-parser is like a translator for cookies in web development. A cookie is a small piece of data that a website stores in your browser, often to remember things like your preferences, login details, or items in a shopping cart. When your browser talks to the server, it sends these cookies along with your request.
Hashing (bcrypt): Hashing is a mathematical process that converts data into a unique, fixed-length string of characters, called a hash value. It's a one-way process, meaning the original data can't be recovered from the hash value.
We can do hashing without bcrypt/argon0 as well- Lets understand the basic concepts first:-
Salt: A random value added to the password before hashing to make attacks like rainbow tables ineffective.
Hashing: Converting the password + salt into a fixed-length hash using a secure algorithm like SHA-256.Storage: Save the salt and hashed password securely, typically in a database.
What’s rainbow table attack you may ask? A rainbow table attack is a password-cracking method that uses a special table (a “rainbow table”) to crack the password hashes in a database. Applications don’t store passwords in plaintext, but instead, encrypt passwords using hashes. After the user enters their password to log in, it is converted to hashes, and the result is compared with the stored hashes on the server to look for a match. If they match, the user is authenticated and able to login to the application.
The rainbow table itself refers to a pre-computed table that contains the password hash value for each plain text character used during the authentication process. If hackers gain access to the list of password hashes, they can crack all passwords very quickly with a rainbow table.
Examples of Rainbow Table Attacks Below, we’ve listed two “real world” examples of how rainbow table attacks might occur.
An attacker spots a web application with outdated password hashing techniques and poor overall security. The attacker steals the password hashes and, using a rainbow table, the attacker is able to decrypt the passwords of every user of the application. A hacker finds a vulnerability in a company’s Active Directory and is able to gain access to the password hashes. Once they have the list of hashes they execute a rainbow table attack to decrypt the hashes into plaintext passwords.
Lets not get side tracked. We were on bycrpt. (If you are still wondering about SHA-256, just google it). Bcrypt: A library to help you hash passwords. ( for more Click Me)
Aggregation Pipelines
Let's talk like a proper SDE, shall we?
An aggregation pipeline consists of one or more stages that process documents: Each stage performs an operation on the input documents. For example, a stage can filter documents, group documents, and calculate values.
The documents that are output from a stage are passed to the next stage. An aggregation pipeline can return results for groups of documents. For example, return the total, average, maximum, and minimum values.
It takes an array, within it accepts multiple objects.
User.aggregate([
{}, {}, {}
])
There are many stages to add, but lets talk about which one I used-
Adds new fields to documents. Similar to | |
Returns a count of the number of documents at this stage of the aggregation pipeline. | |
It checks from other collections: usually you need from: {from where the data is coming}, localfield: {thats currently in the scmea}, foreignfield: {which is stored in DB}, as: {what you will call it} | |
You write the field: 1 or 0, to activate or not, like to show it or not in pipelining. | |
Adds new fields to documents. Similar to | |
| db.collection.find( { field: { $size: 2 } } ); This query returns all documents in |
| Takes three param {if: then: else: } or [{} , {}, {}] |
| { $in: [ <expression>, <array expression> ] } |
| Filters documents based on a specified query predicate. Matched documents are passed to the next pipeline stage. Syntax: { $match: { <query predicate> } } |
pipeline:[] | You can make sub-pipelines inside an aggregate pipeline, and so on, its kinda like inception. |